今回は、新しく発売されたCM4Stackのお話(^^)

なんとなくの見た感じ、サイズ感がM5Stackを彷彿させるもので、まだ発売されたばかりのマシンだ!
M5Stack CM4Stack 開発キット CM4104032搭載www.switch-science.com
おそらくArduinoからの流れを組む、比較的簡単にハードウェア制御が出来るミニコンピュータという位置づけなのだろう。
ハードウェアを全く理解していない私にとっては、小さな液晶とコンピュータがパッケージングされたモノ、という感覚だ(^^;;

多分、ポケコンなどからの流れでこういう(CPU、キーボード、液晶がついてる)マシンが好きなんだろうなーと思う。
M5Stack系の良さをほとんどと言って良いほど使えてないのは自覚してる!(^^;;;
CM4Stack
初めにCM4Stackの名前を見てピンときた。
この界隈でCM4といえばRaspberryPi Compute Module 4が思い浮かぶ(^-^)
身近なところではreTerminalだったりDevTerm RPI-CM4 Liteに入ってたりする。
このボードがM5Stackの筐体に入っちゃうんだろうな…。
そして実際に販売されたCM4Stackの中身にはCM4が入っているんだと思う。
分解してないから見てないけど(^^;;
ということは中身はLinuxマシンなんだろうな…と予想がつく。
TwitterなどにCM4Stackの映像が流れるたびに「どうしようかなぁ…」と悩んでいた。
なぜかと言えば、私は小型のLinuxマシンをいくつも所有してる!
すぐに使える形になっているものもあれば……

箱に入ったままの新品も多数所有している。

つまりいつでもLinuxマシンは使える状態にあるのだ!
こんな状態なのに、さらに新しいマシンを手に入れる必要はあるのか…と葛藤!
散々葛藤した挙げ句、決めた!
一個だけ手に入れよう!(^-^)
よし、一件落着♪(^o^)
届いたCM4Stack
CM4Stackが届いてからの開封の儀式はいろんなところに出ていると思うので、私は使い始めるところから!(^^)
最初はHDMI経由のモニタ、USBにマウスとキーボードを繋げて、付属の電源と本体を繋げる。HDMIで繋げたモニタにはRaspberryPiで見慣れたデスクトップ、液晶にはCM4 STACKの表示が出る。
ネットワークケーブルを接続しておけば、液晶画面にIPアドレスが表示される。
HDMI側のモニタを操作をしてSSHを有効にすれば(raspi-configを使うのが楽ちんだよ!)、その後はssh経由でログインする事が出来る。
そしてログイン出来てしまえば………あとは普通のLinuxマシンだ(@_@)
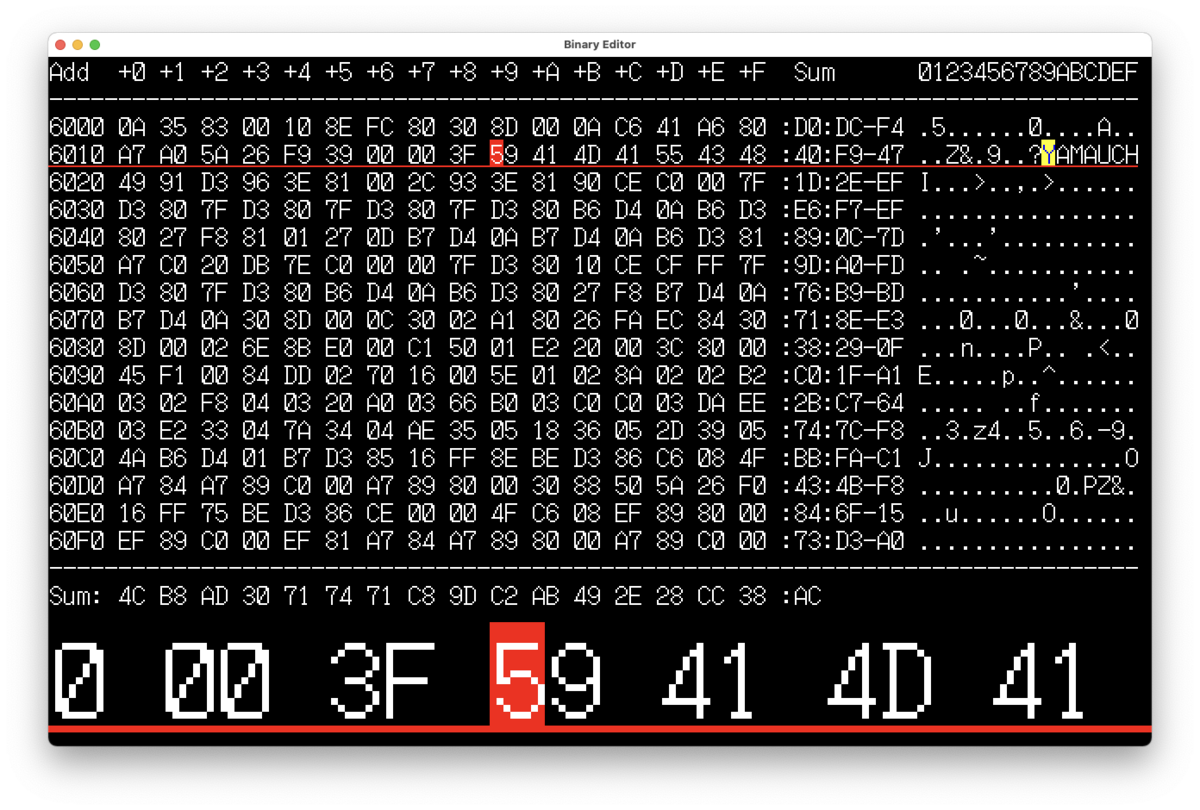
おもむろに cat 適当なファイル > /dev/fb0 としてみる。

お、液晶画面側の絵が壊れた!(^-^)
よーしよーし!!(^o^)
…と思ったら、メモリ使用量とロードアベレージの数字だけが再表示されてしまった…。
(ここの写真を取り忘れる痛恨のミス!)
どのプロセスが表示させてるんだろう…とあれこれ探すが見つからない…。
うーん、どうしようかな…。
でも先にOSの再インストールをしてみる事した!
基本的には書いてある通りの手順で問題なく進んだが、私は過去にreTerminalのOSをアップデートする際、rpibootをMacにインストールしていた。
その部分は手間が省けたので楽チンで済んだ(^-^)
OSをインストールし直したら、液晶画面に表示されているCM4 STACKの表示が消えた!
私の使い方だったら復活させる必要もないかな…って事で、このまま使う!(^-^;;
とりあえずX68000!
今回はX68000エミュレータを動かしてみたら、それで満足しそう!
だってFM-7とかPC-8801とかCP/M80とか、もはや動くのが当然なスペック…。私としては「メモリもない、CPUパワーもない。でも動かしてみる!」が好きなので、CM4Stackではスルーしようかなーと思ってるw
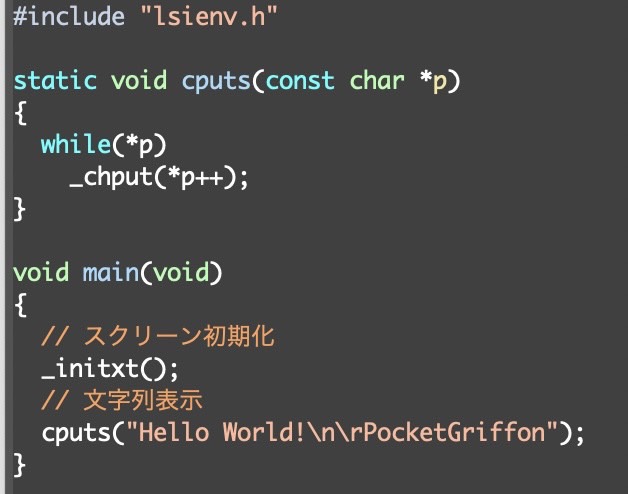
フレームバッファへ直描きするX68000エミュレータと言えば、過去にポメラDM250や、電子手帳Brainなどで何度も挑戦している!
このプログラムをssh経由で持ってきて、なーんも考えずにmakeってすれば、一発で動いたりしないだろうか…?(^-^;;

あー……さすがにそこまで甘くなかった(^^;;
CM4Stackのフレームバッファは深度16bitだったので、(最初のポメラ用に書かれた)深度32bitを前提に書かれたプログラムの一部は修正をした(^^)
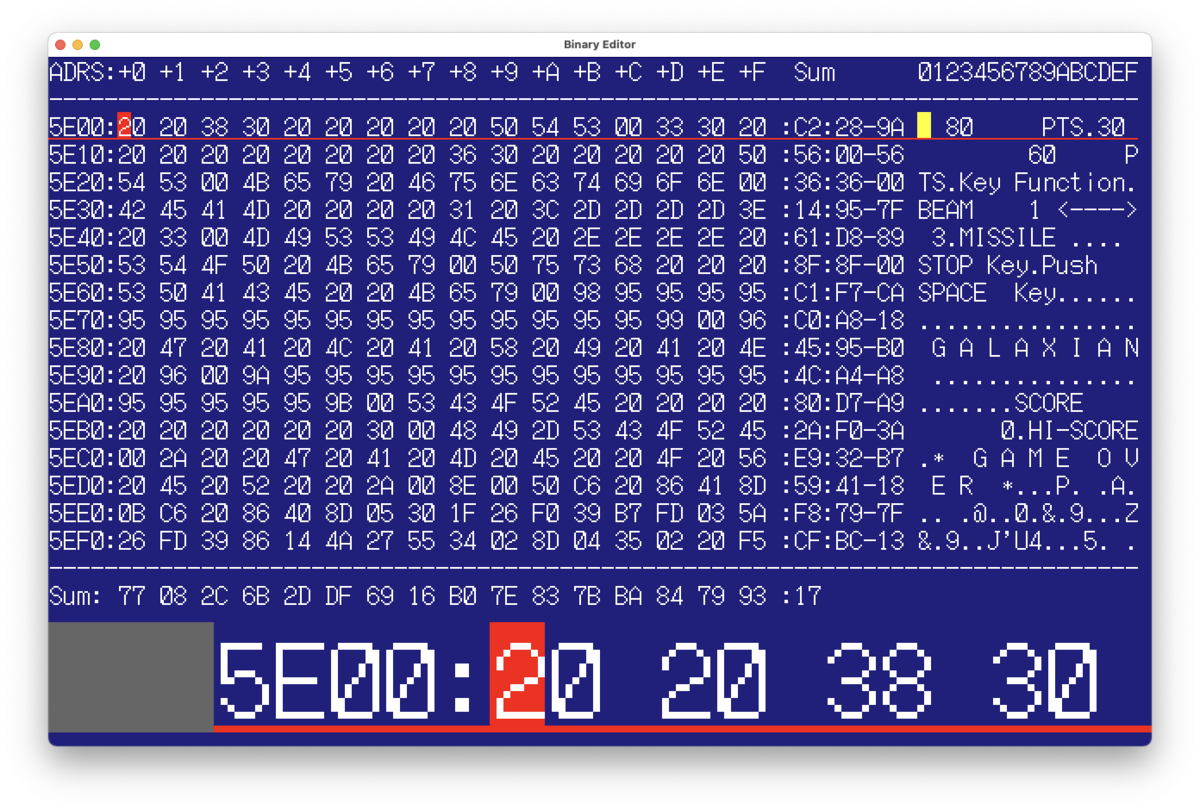
どうやら画面を90度回転させてやる必要があるみたいだ!
単純に縦横を入れ替えるだけなのでプログラムは超単純だけど、離れた位置にあるメモリを頻繁にアクセスするためキャッシュがミスしまくって劇遅になる…とかないだろうか??
… → やってみたら全然気にする感じでは無かったんだけどね(^^;;

無事に横向きに表示された!(^-^)

ちなみに画面に入り切らない部分については、無理に圧縮して表示などはせずはみ出たところは表示しないという消極的な方法を取ったw
実用性よりも動くことを優先させた結果だ!←言い方
CM4Stackで動かすX68000エミュレータ!(px68k)
— PocketGriffon (@GriffonPocket) 2023年4月8日
お約束のSION2を動かしてみた。
最初の30秒くらい飛ばすとゲーム画面になるよ!
USBハブで繋げたスピーカーで音を鳴らしてる。
常時冷却ファンが回っててノイズが凄いので音量注意!
CM4Stackのパワーなら余裕で動いちゃう。#CM4Stack #X68000 pic.twitter.com/RDoUqGDJbu
この辺りは普通のLinuxプログラムなので、目新しいところが何も無い…(-_-;;
おわりに
とにかく速いCM4Stack!
このサイズでこのメモリとパワー……かなりのオーバースペックなのでは?(^^;
使っていると動いてる時間の半分くらいはファンが回りっぱなしとなる。今の時期でも回ってるので、夏場は熱対策が厳しくなるかも知れない。私は小型のファンを回して冷気をCM4Stackにあてながら作業をしていた。
そうしないと大変熱くなるのだ(^^;;
M5Stackの最新ハードという事でいそいそと手に入れてみたけれど、私のような明確な目的も無く手に入れてしまうと、過去の資産を動かして終了となってしまう(^^;;
それよりもCM4Stackの魅力は外部ハードとの連携があるんだろうから、そちらに強い方が触ったらもっと魅力を発揮できるんだろうなー…汗
ではまた次回!(^-^)ノ