先日、SHARP PC-1600KでBad Apple!!を表示させる実験をした。
主な目的は、搭載されているメモリを使い切る「何か」をしてみたかったのであり、それ以上の目的も目標もないままだった。
Twitterおよびこのブログに投稿後、改めてYoutubeなどにあるBad Apple!!の動画を見てみたが、音楽と映像がマッチしていてとても軽快に見られる!うーん、これは…サウンドはどうあれ動画速度はもう少し速めないと制作者に失礼だなぁ…と思った。
というわけで!今回は高速化がメインのお話(^-^)
速度計測をしてみる!
さっそく高速化を始めてみたい……が、その前に速度を正確に計測する仕組みが必要だ。
その仕組みが無いと、実際に入れたコードで速度が速くなったのか、逆に遅くなってしまったのかを知る方法が無い。人間の感覚ほどアテにならないモノはないw
どこかのI/OポートにTick値が出てないかな…。タイマー割り込みでも良いのだが…。
エミュレータがあれば楽に速度計測が出来けど、そのためだけに作るのは忍びない(否定はしないw)。
そしたら「PC-1600K データブック」に情報が載っていた。

こういう情報が掲載されている書籍があるのは、本当に助かる!
だがしかし……なんと1/64秒の割り込みしか用意されていなかった!処理速度を測るための数値としては、だいーぶ大雑把な数字だ。うーん…これで測るしかないかなぁ…。
サンプリング数を多くして、大きな値で見ていくしか無いな。
現状、64KBの拡張メモリ(CE-1600M * 2)に1086枚の画像が入っている。これを全て表示させた後に掛かった数字(時間)を目安にする。
初期の状態では「10784」という数字が出た!
この数字を64で割ると、表示に掛かる秒数が出てくる(168.5秒)。1086枚の画像を168.5秒で表示しているので、秒間6.445枚の絵が表示出来ている。これが現状だ。
最初が秒間1枚くらいの速度だったので、まぁ速くなってはいるんだけど(^^;
オリジナルが秒間30枚らしいので、それから比べたらだいーぶ遅い。
高速化開始!
さて、正確な(でも大雑把な)速度が測れるようになったので、これから楽しい高速化作業といきますか!
まずは「何を高速化するのか」を検討してみる。
処理の流れは、ものすごく乱暴に書いて以下の通り。
1、画像を展開するバッファをクリア
2、圧縮されたデータをバッファへ展開
3、展開されたデータをVRAMへ転送
この3つだ。
1のバッファクリアは、点を打つ/消す、のどちらかの処理を端折るために入れている。先にクリアされている事が保証されれば「点を消す」処理はいらなくなる。黒い部分が多い画像では逆に不利となるが、多くの場合は有利に働くため入れている。
2は多分、イチバン重たい処理。データによって縦方向と横方向があり、2つの展開ルーチンが存在する。縦方向に圧縮されたデータが多いため、縦方向のルーチンを最適化したい。
3はIOCSの処理をそのまま利用している。問題は横方向の156ドット全てを転送するサービスしか提供されてなく、なんとなく無駄が多そう…という事だ。
それぞれの速度を測ってみたが、1はほとんど負荷がなく誤差の範囲程度、3は全体の25%くらい掛かっている事が分かった。残りが2の時間だ。
実際の描画処理は、最終的にはアセンブラ化すればいいか…と思っているが、でもC言語で究極まで高速化してから、そのアルゴリズムでアセンブラ化するのが良いかなと思ってる。LSIC-80が出力するアセンブラコードを参照しながらコードに手を加えていくが、むしろ「アセンブラコードでこう吐かせたいから、C言語でこう書く」という感じ(^^;;
久しぶりにLSIC-80でガリガリ組んでみたが、register宣言でコードをコントロール出来たり、auto変数よりもグローバル変数の方が良いコード吐いたりなど、自前コントロールがとてもし易いコンパイラだと思い出した。
その結果、「これをアセンブラ化してもたいして速くならん」というところまで攻め込む事が出来たので、これはもうコレで(^^;; C言語状態で満足いくモノが出来てしまったw
まぁデータの持ち方などアルゴリズムを変更したら良かったな…と思うところがいくつか出てきたが、今回はこれ以上はやらないという事にした(^-^; キリ無いからね!
LCDCを直接アクセスしたい!
3の「展開されたデータをVRAMへ転送」を高速化してみる事にした。
実はIOCS経由でしかLCDにアクセス出来ない事が気になってた!(^-^;; 「出来ない」というと言い方がアレだけど、「やり方を知らない」と言った方が良いかも。
「PC-1600K データブック」にもLCDへの直接アクセスは詳しく書かれて無いのだ!
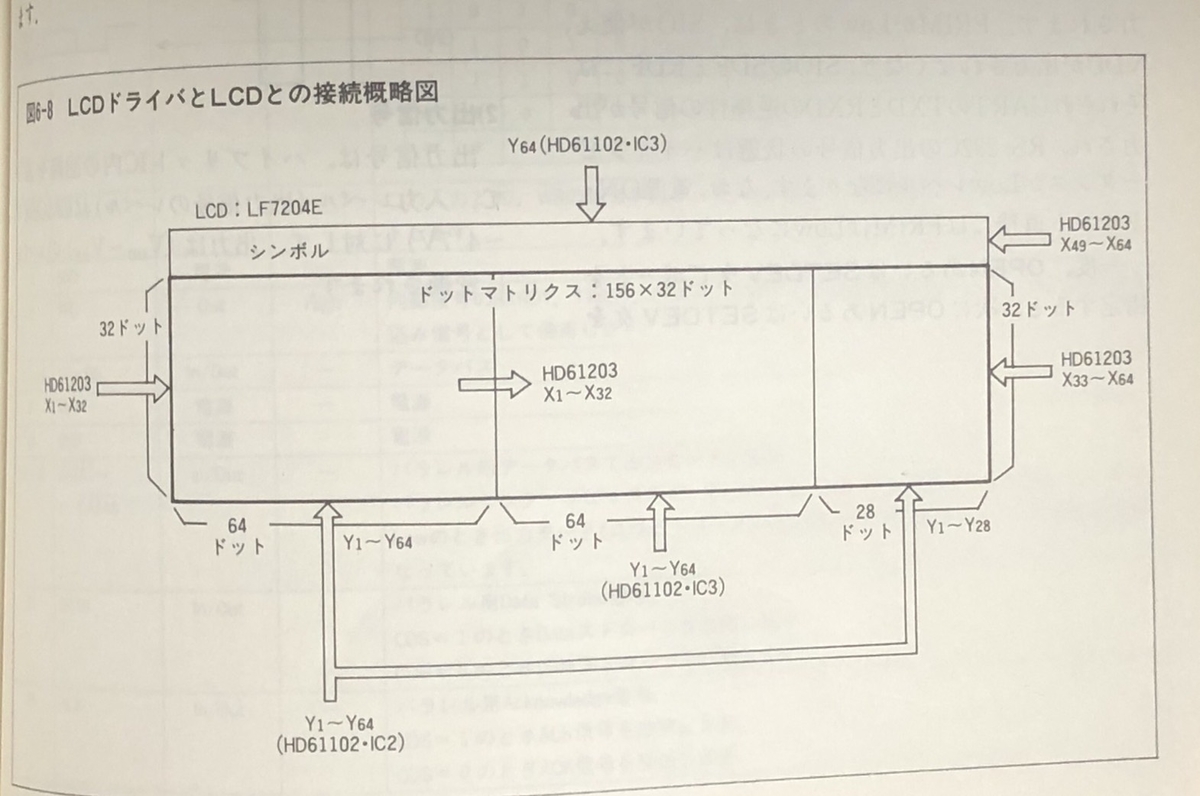
↑この図しか書かれてなかったんだけど…見る人が見たら理解できるんだろーか?
なんとなく分かるのは、左64ドットと次の64ドットではコントローラが違うらしい事、右の28ドットも特別扱いっぽくなってるらしい…。
ここから理解できるのは、表示しようとするモノが「真ん中の64ドット境界」をまたぐと処理が面倒になりそう…って事だ。
詳しいI/Oポート情報が欲しい!
仕方ないので…ROMを解析する事にした!
最低限ではあるけれども分かった事を書いておく。
I/Oポート58h〜5Ahをアクセスすると左64ドット、右28ドットがアクセス出来る。
58hがLCDの座標設定、59hのMSBにBusy信号、5Ahにデータを出力する…らしい。これが左64ドットをアクセスする時。右28ドットにアクセスする際にはY座標の指定を+4する。今回は使わないけど!
そして中央の64ドットにアクセスするには54h〜56hポートをアクセスをするようだ。
なるほど…そういう感じなのか。
これらを組み立てる事で、IOCSの156ドット全てではなく、必要最小限のドット数のみ更新する事が出来そうな雰囲気。
どうやらPC-1600Kにはハードウェアスクロールっぽい仕組みがあるようで、オフセット座標を加算しないといけない事に気が付かずに一晩ハマった。その後、なんとか問題を解決してLCDCへの直接アクセスが可能となった!
その影響として、画面中央に表示していた画像が、左から64ドットに変更となった。でもそのおかげで効率の良い表示が出来るようになった。
LCDCの速度はPC-G850シリーズのそれとは違い、CPUの速度に追いついてこない。Z80のOTIRで一気に転送ってのはLCDCの速度的に無理で、1バイト送信するたびに40クロック以上待つか、律儀にBusy信号を監視する必要がある(今回はちゃんとBusy信号を監視した)。
※PC-G850Sで実験した際には、OTIRどころかOUTIを144個並べても問題なかった
以上の工夫をする事によって、初期状態で10784(168.5秒)掛かっていた処理が、6378(99.65秒)まで縮める事が出来た!

この先、圧縮データの展開処理をアセンブラ化としたとしても、6000を切る事は難しいかも知れない。とりあえずこの辺りでキリを付けるのが良いかな…と考えた。
動いたばかりの時は秒間1コマしか動かなくて、こりゃどうしたらいいんだろう…と思ったが、なんとかアニメーションっぽく見えるようになったのは嬉しい(^-^)
データ量もどどーんとでっかいし、とりあえず満足かな!
PC-1600KでBad Apple!!を高速化してみた!秒間10画像まで表示出来るようになったけど、今の仕組みだとこれが限界かなぁ…(^^;
— PocketGriffon (@GriffonPocket) 2021年2月26日
動画の撮り始めにカメラが揺れてしまった! pic.twitter.com/wpFxOxxHAq
最初に公開した状態↓に比べても速くなってるのが分かると思う(^^)
PC-1600KでBad Apple!!(の一部)を表示させてみた!表示が遅くてイライラするかもw pic.twitter.com/NNdOA4KKkx
— PocketGriffon (@GriffonPocket) 2021年2月21日
これをやってる最中に気が付いてしまったんだけど……ウチのFX-890Pだったらメインメモリが256KBあるなぁ…とか、PC-E500に取り付けてある増設メモリも256KBだったなぁ…なんて思ってしまった。やらないよ!やらないんだからね!(TOT)
ではまた次回!(^-^)ノ